Tablespace
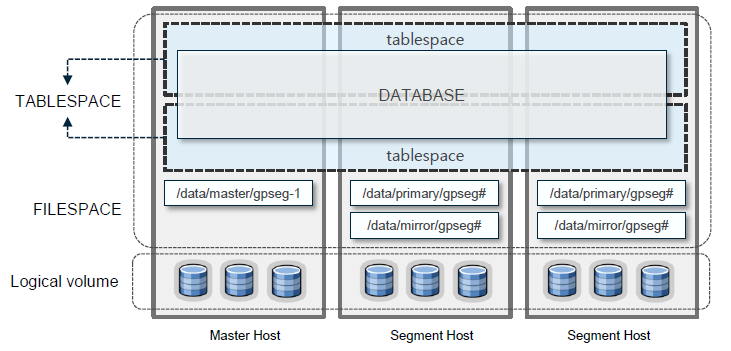
- Tablespaces sit atop filespaces interacting with the underlying filesystem
- A filespace can support multiple tablespaces
- default tablespace : pg_default, pg_global
- 주요 명령어
Partitioning
- 논리적으로 큰 테이블을 작은 부분으로 나누는 것으로, query performance 향상에 도움이 됨.
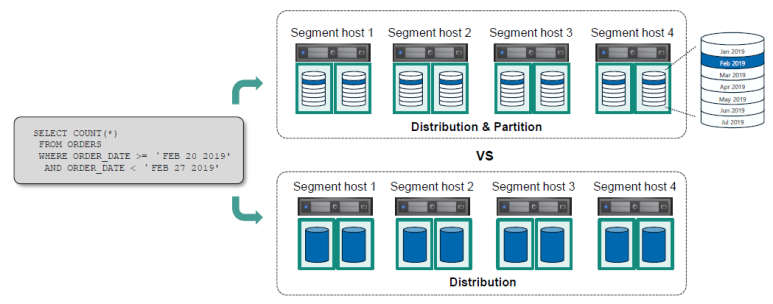
- 전체 테이블에서 distribution key 를 통해 segment 별 접근양을 줄이고,
segment 내에서 파티션을 통해 더 축소 (아래 그림 참고)
- 주요 쿼리 조건으로 빈번하게 사용되는 키를 partition key 로 사용하는 것이 좋음.
- 분산키는 cardinality 가 높을수록, partition key 는 cardinality가 낮을수록 (분산키와 반대)
- partition 테이블이 생성되면, parent-child 로 테이블이 구성되며 실제 데이터는 child table에서만 조회됨.
- 생성할 때만 지정 가능하며, 일반 ↔ 파티션 테이블 변환 불가
- 종류 : range partitioning, list partitioning
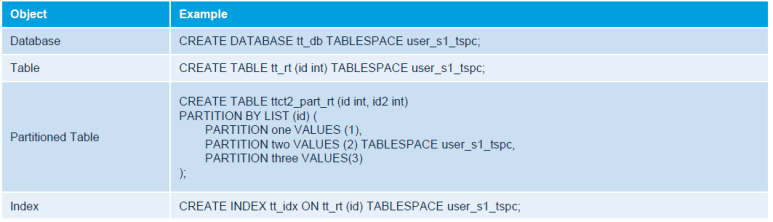
DDL 샘플 코드
1) PARTITION TABLE
- DEFAULT PARTITION 주의점
. DEFAULT에 데이터가 많이 들어가는 경우 확인 필요
. OPTIMIZER가 무조건 체크하도록 하는 로직이 있음(I/O 가 무조건 추가됨)
- 최초 생성 후 START~ END 날짜 변경 가능? --> add partition 으로 이후 날짜 추가 가능
CREATE TABLE PARTITIONED_TABLE
(
OPERATIONID INTEGER ,
MEMBERID
INTEGER ,
ATTENDINGDATE
TIMESTAMP WITHOUT TIME ZONE,
HISTOLOADID
SMALLINT
WITH (APPENDONLY=TRUE, ORIENTATION=COLUMN, COMPRESSTYPE=QUICKLZ)
DISTRIBUTED BY (MEMBERID)
PARTITION BY RANGE(ATTENDINGDATE )
( START ('1999-03-01') END ('2012-01-01')
EVERY (INTERVAL '1 MON')
WITH (APPENDONLY =TRUE, ORIENTATION=COLUMN, COMPRESSTYPE QUICKLZ ),
DEFAULT PARTITION EXTRA
WITH ( APPENDONLY =TRUE, ORIENTATION=COLUMN, COMPRESSTYPE QUICKLZ);2) SUB PARTITION TABLE
- 적절한 child partition 구성 중요
(child partition 수 증가 → pg_catalog 증가 → 모든 쿼리에 대해 child partition I/O 증가)
CREATE TABLE SALES (ID INT , YEAR INT , MONTH INT , DAY INT , REGION
DISTRIBUTED BY (ID)
PARTITION BY RANGE (YEAR)
SUBPARTITION BY RANGE (MONTH)
SUBPARTITION TEMPLATE
( START (1) END (13) EVERY (1), DEFAULT SUBPARTITION OTHER_MONTHS)
SUBPARTITION BY LIST (REGION)
SUBPARTITION TEMPLATE
( SUBPARTITION USA VALUES ('USA'),
SUBPARTITION EUROPE VALUES (' EUROPE'),
SUBPARTITION ASIA VALUES ('ASIA')
DEFAULT SUBPARTITION OTHER_REGIONS)
( START (2002) END (2010) EVERY (1), DEFAULT PARTITION OUTLYING_YEARS);
3) PARTITION 저장 옵션 바꾸기
CREATE TABLE TRAINING.TMP_TABLE_FACT_PARTITION_1_PRT_29
(LIKE TRAINING.TABLE_FACT_PARTITION_1_PRT_29)
WITH (APPENDONLY=TRUE,ORIENTATION COLUMN,COMPRESSTYPE ZLIB,COMPRESSLEVEL =4);
INSERT INTO TRAINING.TMP_TABLE_FACT_PARTITION_1_PRT_29
SELECT * FROM TRAINING.TABLE_FACT_PARTITION_1_PRT_29;
ALTER TABLE TRAINING.TABLE_FACT_PARTITION
EXCHANGE PARTITION FOR ('2009-04-01 00:00:00')
WITH TABLE TRAINING.TMP_TABLE_FACT_PARTITION_1_PRT_29;
4) 이외 PARTITION 관리 스크립트
/* Add a partition to an existing partitioned table */
ALTER TABLE sales ADD PARTITION
START (date '2009-02-01') INCLUSIVE END (date '2009-03-01') EXCLUSIVE;
/* Rename a partition */
ALTER TABLE sales
RENAME PARTITION FOR ('2008-01-01') TO jan08;
/* Remove a partition */
ALTER TABLE sales DROP PARTITION FOR (RANK(1));
ALTER TABLE TAB_PART DROP PARTITION [IF EXISTS]
{ PARTITION_NAME | FOR (RANK(NUMBER)) | FOR(VALUE) } [CASCADE];
/* Truncate a partition */
ALTER TABLE sales TRUNCATE PARTITION FOR (RANK(1));
/* Exchange a partition */
ALTER TABLE sales
EXCHANGE PARTITION FOR ('2008-01-01’) WITH TABLE jan08;
/* Split an existing partition in a partitioned table */
ALTER TABLE sales
SPLIT PARTITION FOR ('2008-01-01’) AT ('2008-01-16’)
INTO (PARTITION jan01to15, PARTITION jan16to31);
## 분산 vs 파티션
|
분산
|
파티션
|
|
|
목적
|
데이터를 모든 SEGMENT 로 분산하여 비슷하게 처리 할 수 있도록
|
각 SEGMENT 내부에서 더 적은 데이터를 조회할 수 있도록
|
|
cardinality
|
↑
|
↓
|
|
filter 조건 컬럼으로 설정
|
filter 조건 x (날짜형)
|
filter 조건 (날짜형)
|
|
주의 사항
|
- default partition 주의
(I/O 가 무조건 1번 더 생김)
- 과도하게 많은 PARTITION
(catalog ↑ → query plan ↑)
|
☆ Tip! Partition 생성 관련 가이드
각 Segment host 내 접근하는 segment 를 최대 1G 씩 잡는 것이 좋음.
예를 들어 host 10개, host 당 segment 개수가 8개라면,
1개의 partition 당 물리적으로 80G (압축 후) 정도 파일을 사용하도록 잡으면 최적이나 아니더라도 상관은 없음.
Temporary table
- 세션이 끝나면 drop 되는 임시 테이블
- 일반 테이블과 동일하게 분산되어 저장되며, compression, index, analyze, PK 등 설정 가능
- Use Case
- Subset of large tables
- Data transform of ETL, Batch process
- Another distribution for better join
- 일반 테이블과 달리 TEMP TABLE은 미러링 공간을 사용하지 않고 커밋하나, 중간에 중지되는 경우 추적이 안됨 (I/O 절반)
- normal table : write-ahead log 적재o, 미러링 o
- temp table : 세션이 중지되면 데이터가 사라짐(추적x), 미러링 x
- unlogged table : 세션이 중지되도 데이터가 남음. 미러링 x
>> etl 등에서 truncate , insert 사용하면 유용

- Example
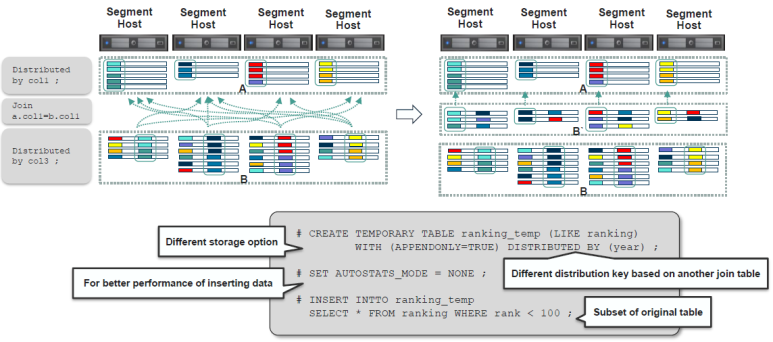
기존 테이블 간의 join 에서 local join 등이 되지 않아 성능이 나오지 않는 경우,
아래와 같이 진행하여 해결하는 방법이 존재한다.
1) temp table 생성
2) temp table 과 local join 하여 쿼리 실행
☆ Tip
기본적으로 GPDB 의 경우, 아무때나 통계정보를 업데이트 하기도 하는데,
최초 데이터를 넣을 경우 해당 모드를 끄고 데이터를 모두 넣은 후 직접 통계 등을 돌려주는 것이 좋다.
- SET AUTOSTATS_MODE=NONE; --초기 데이터를 넣을때 성능을 개선할 수 있는 모드
Quiz
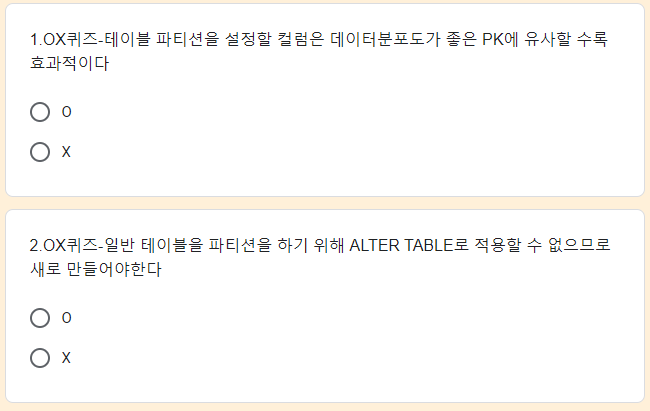
x (파티션은 그룹핑이 좋을 수록), o
'프로N잡러 > 프로그래밍&자격증' 카테고리의 다른 글
| [SQLD] 자격증 정보 & 기출문제 웹사이트 (0) | 2024.01.09 |
|---|---|
| [SQLP] 기출문제 웹사이트 (0) | 2024.01.09 |
| [GPDB] 4-4. Data Definition Language(DDL) : Indexes, View, Sequence (0) | 2024.01.09 |
| [GPDB] 4-3. Data Definition Language(DDL) : Data Types (0) | 2024.01.09 |
| [GPDB] 4-2.Data Definition Language(DDL) : Distribution (1) | 2024.01.09 |


